推荐系统算法整理
个性化推荐
场景决定推荐规则
推荐分类
1.基于规则的推荐
规则模型:规则定义,简单的算术公式
2.基于传统机器学习的推荐
个性化召回als算法原理:
个性化排序lr算法原理
点击率预估模型算法
推荐算法的好坏取决于用户历史数据
3.基于深度学习的推荐
深度学习是机器学习的升级版,也是基于神经网络的进化,可以更深层次的发现用户的需求,但是对数据的真实性要求更高
推荐模型
规则模型:规则定义,简单的算术公式
机器学习模型训练:数据训练后的算术公式
通过历史行为的数据,去训练出算术公式,训练出来的算术公式可以用来做机器学习模型预测
机器学习模型预测:待预测数据经过训练模型算术公式后的结果
模型评价指标
离线指标:查全率,差准率,auc等
80%的数据用做模型训练得出算术公式,然后用剩下20%的数据用做模型预测,得到的结果和真正的结果作比较,这样可以衡量算法公式的优劣
在线指标:点击率,交易转化率等
在线指标远比离线指标重要
A/B测试:简单来说,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录下用户的使用情况,看哪个方案更符合设计目标。
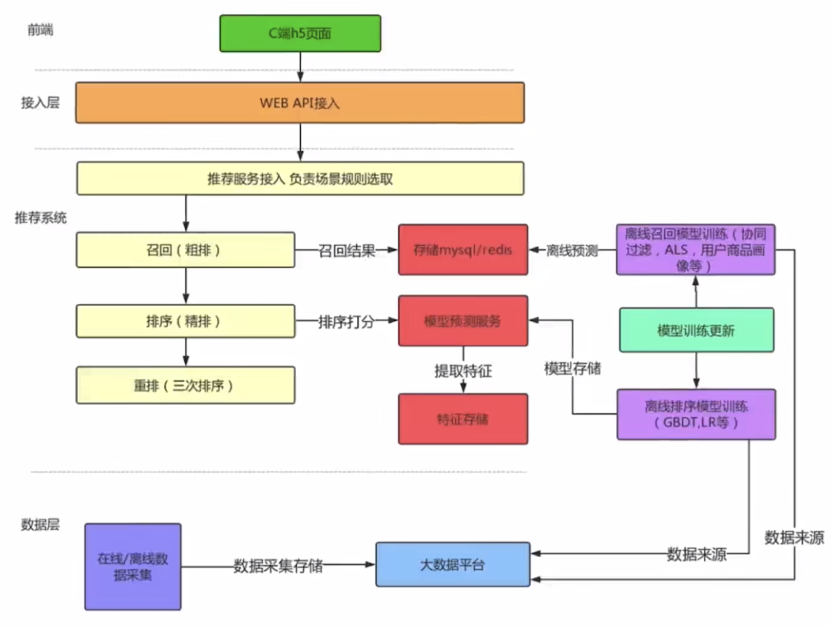
推荐系统架构
个性化召回算法ALS
ALS(Alternating Least Squares,):最小二乘法,利用矩阵分解的结果无限逼近现有数据,得到隐含特征,最后利用隐含特征预测其余结果
演算步骤:
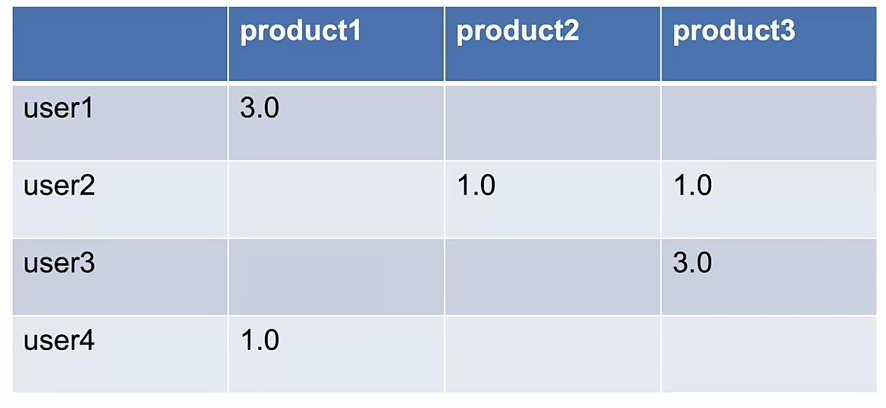
User 4行 Product 3列
游览行为—1分
游览+购买行为—3分
预测空白区域:
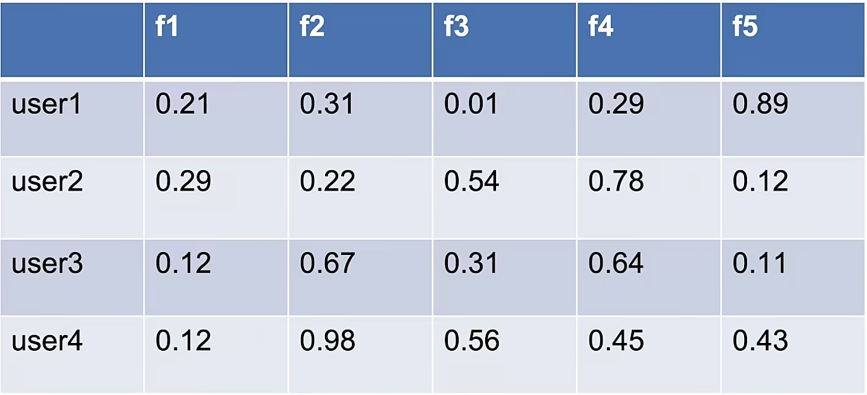
User 4行 5列隐式特征
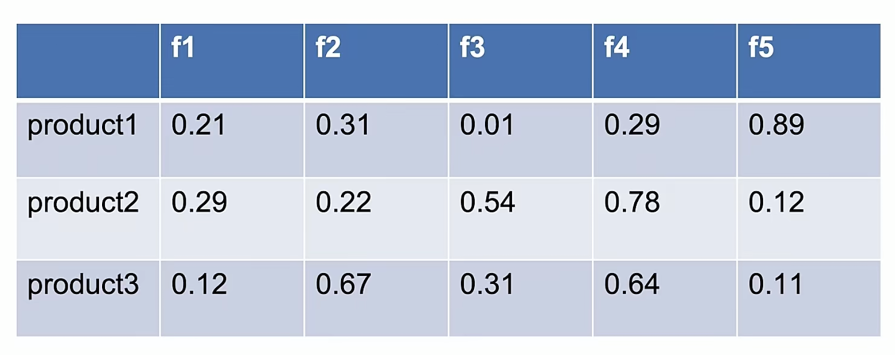
Product 3行 5列隐式特征
User矩阵*Product的转置矩阵,也就是User的f乘Product,获取无限逼近于真实数据的分数,同时预测其余节点的分数,排序后输出
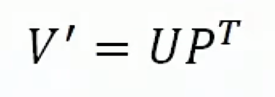
个性化排序算法LR
逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种
Y=ax1+bx2+cx3+dx4+….. x为特征,a,b,c,d为权重
排序的问题在某些意义上也可以看成是点击率预估,公式中x1x2x3这些可以看成是用户的特征,例如x1是年龄,x2是性别等等,在公式中,每个特征都有一个权重a,b,c,d,e等,结果会得到一个Y,越趋近1代表点击概率越大。这是个预测的过程。
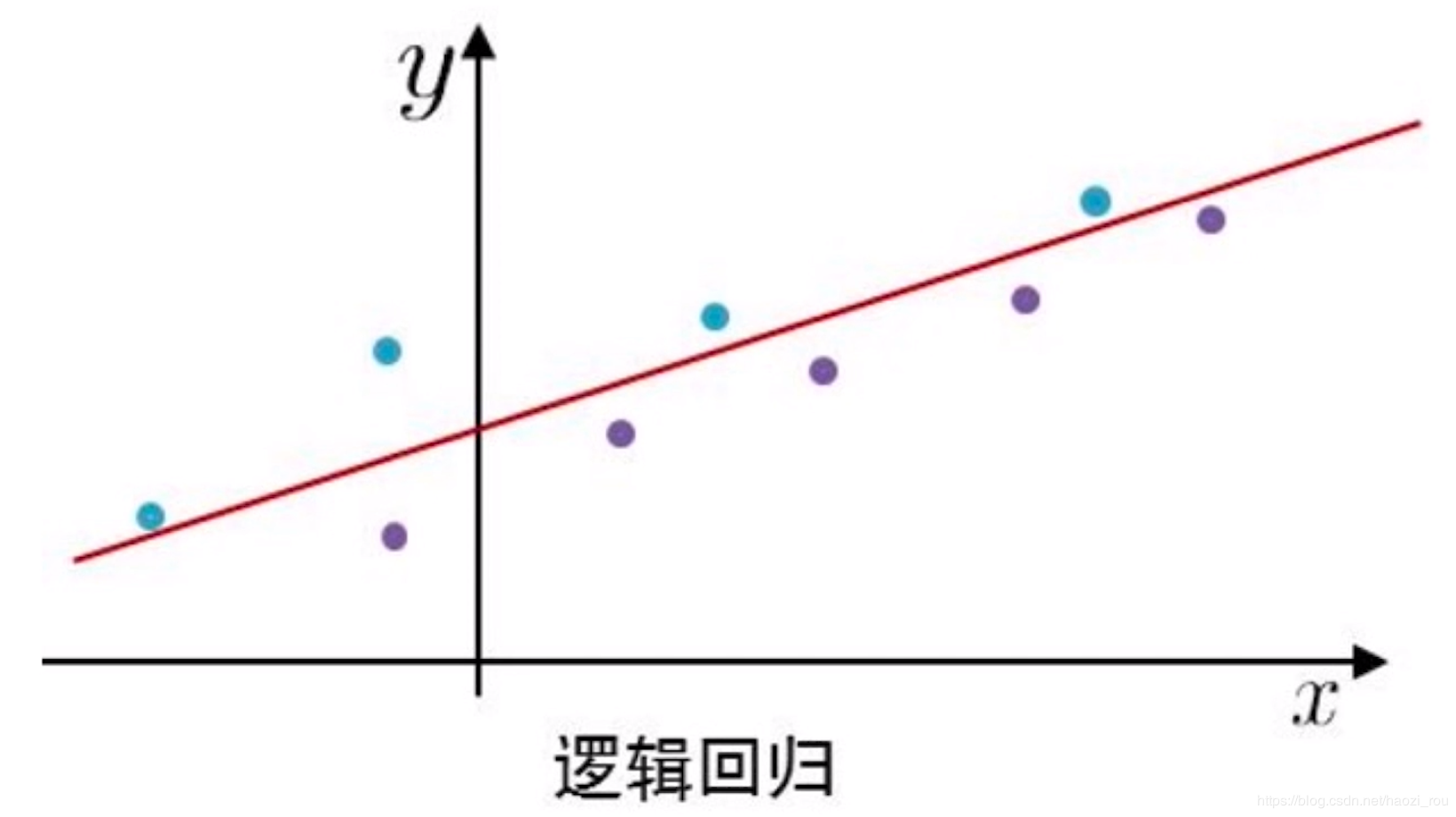
LR算法也就是要算出a,b,c,d,e,在大数据平台会采集Y的样本,可能是1也可能是0,
在上面中,蓝色为正样本,紫色为负样本,也LR需要推算出红线,等学习出红线以后,就可以做预测了,新进来一个x点,可以根据红线来推算这个点是正样本的概率大还是负样本的概率大。这就是比较简单的逻辑回归的排序算法原理。
决策树算法
决策树算法,事实上是一个多重分类选择器组合承德结果,也就是输入一个参数,根据这个参数返回1/0,举个例子的话,可以想象成以前杂志上的那种心理测试题。通过多个选择,获得一个结果。
那么如何定义决策树的每个节点的特征呢?原则上越能分出绝大部分特征的越往上。
如何衡量?数学上有一个名词叫做信息熵,来衡量信息量的大小,也就是对随机变量不确定的一个衡量,熵越大,不确定性越大。
例如:天气有晴天、多云、雨天,温度有冷、热、适中,湿度有高、中等,风有有风、无风,最后有个结果,是否出去玩。
那么我们如何构建这个抉择树?我们选取熵大的节点放在上面,依次往下。离散特征直接按照分类选择器,连续特征可以用二分、三分等分类方式进,例如小20岁,20-40等等。
决策树的缺点:样本特征过多时,树的高度太高。样本特征本身有问题时,如果过拟合,会对预测产生偏差。
为了避免决策树的缺点,我们对决策树衍生出了两种算法:随机森林法和GBDT
随机森林:通过随机的选择样本(放回抽样),也就是随机选择几个样本,几个特征,生成一个决策树,放回去再随机选择样本生成决策树,这样就可以生成随机森林。最后在测试阶段,把所有决策树的结果汇总到一起取平均数。当然,随机的缺点也就是不确定性,既是优势、又是劣势。
基于这个,衍生出了另一种算法:GBDT
顺序为:
1 | 1.从初始训练集中得到一个基准学习器。 |
对于GBDT,它是以第一棵树作为基准,逐步调整,所以这样出来的树也就更准确了。
机器学习模型实战
Spark原理
Spark是为大规模数据处理而设计的快速通用的计算引擎。
他有很多的库,例如Spark core、Spark Sql、Spark on Hive、Spark Streaming等。还有机器学习库例如
Spark mllib:机器学习库。
Map Reduce概念:
现在有一个场景,有一个list,里面存的是商品实体,现在需要将这些实体中的id提取到另一个list中,现有阶段就是遍历然后把id提取出来,不管是for还是lambda还是别的方式。但是如果这个list里面的数量非常巨大,那么在jvm内存中做这些事情是不现实的,因此,有了Spark core的Map Reduce,可以将复杂的操作封装成RDD的操作,使我们可以很轻易的进行数据转换。
那么它的原理也很简单,假如有十万条数据,那么spark会拆分成若干条,然后分发给对应的机器,map以后再把所有的数据合并,进行计算如max、min、avg等,然后把结果发给目标机器。
那么对于数据库来说,假如分了三个库,每个库里面都有100w条数据,spark有一个spark sql的库,可以根据很简单的语句 例如:select sum(price) from shop来去获取三个库的数据并返回结果。
Spark Streaming是指假如有个数据采集的系统,数据是以流式byte[]的形式发送给spark,定义4个为一个数字,那么spark就可以通过流式处理的方案处理数据运算。