ElasticSearch7学习笔记
ElasticSearch原理及部署
中文官网:https://www.elastic.co/cn/elasticsearch/
阮一峰:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
搜索原理
ElasticSearch是独立的网络上的一个或一组进程节点,对外提供搜索服务(http/transport协议),对内就是一个搜索数据库。
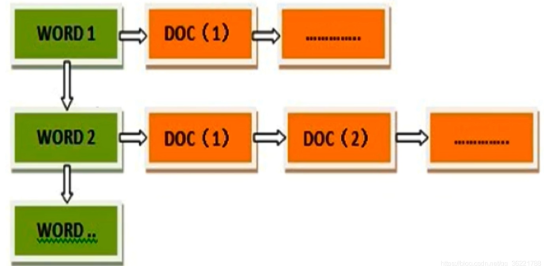
对于搜索,是以词为单位做最基本的搜索单元,依靠分词器构造分词(其中英文分词器有空格分词器),然后用分词构建倒排索引。
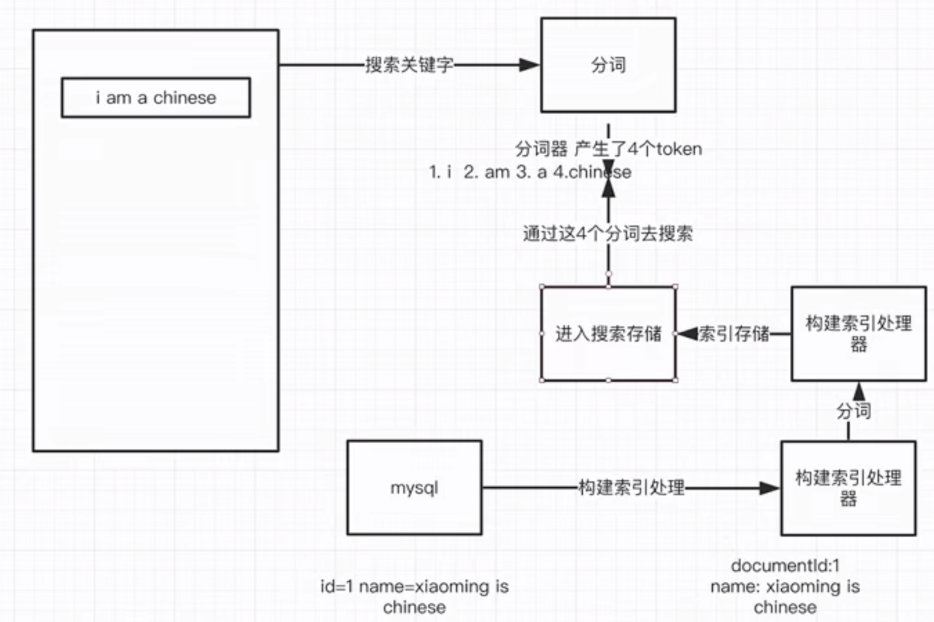
正向索引
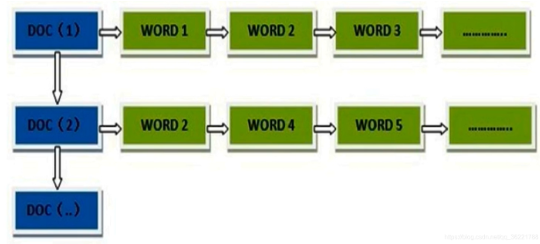
倒排索引
试想根据某个词查找,查找出一堆文档,那到底是哪个匹配度更高呢,这时候就需要打分的逻辑
- TF:词频,这个document文档包含了多少个这个词,包含越多表明越相关
- DF:文档频率,包含该词的文档总数目
- IDF:DF取倒数
- 打分常用计算公式:TF * IDF
名词定义
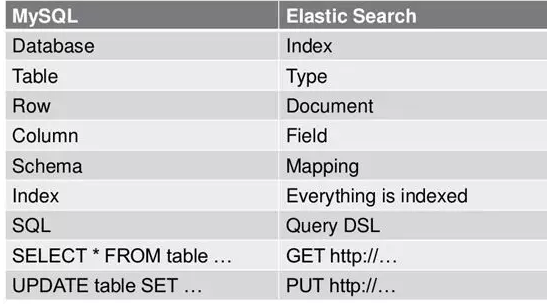
关系型数据库MySQL对应ElasticSearch:
- MySQL 中的数据库(DataBase),等价于 ES 中的索引(Index)。
- MySQL 中一个数据库下面有 N 张表(Table),等价于1个索引 Index 下面有 N 多类型(Type)。
- MySQL 中一个数据库表(Table)下的数据由多行(Row)多列(column,属性)组成,等价于1个 Type 由多个文档(Document)和多 Field 组成。
- MySQL 中定义表结构、设定字段类型等价于 ES 中的 Mapping。举例说明,在一个关系型数据库里面,Schema 定义了表、每个表的字段,还有表和字段之间的关系。与之对应的,在 ES 中,Mapping 定义索引下的 Type 的字段处理规则,即索引如何建立、索引类型、是否保存原始索引 JSON 文档、是否压缩原始 JSON 文档、是否需要分词处理、如何进行分词处理等。
- MySQL 中的增 insert、删 delete、改 update、查 search 操作等价于 ES 中的增 PUT/POST、删 Delete、改 _update、查 GET。其中的修改指定条件的更新 update 等价于 ES 中的 update_by_query,指定条件的删除等价于 ES 中的 delete_by_query。
- MySQL 中的 group by、avg、sum 等函数类似于 ES 中的 Aggregations 的部分特性。
- MySQL 中的去重 distinct 类似 ES 中的 cardinality 操作。
- MySQL 中的数据迁移等价于 ES 中的 reindex 操作。
分布式原理
https://www.cnblogs.com/jajian/p/10176604.html
集群搭建
https://liuurick.github.io/2020/10/11/ElasticSearch%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA/
ElasticSearch基础语法及应用
索引创建,更新,删除
结构化索引,类似MySQL,我们会对索引结构做预定义,包括字段名,字段类型等;
非结构化索引,就类似Mongo,索引结构未知,根据具体的数据来update索引的mapping。
那么如何选择两种索引呢,还是跟具体的使用场景有关,结构化相比非结构化,更易优化,性能好些,非结构化相较灵活,只是频繁update索引mapping会有一定的性能损耗。
1 | #1.索引创建 |
索引简单语句
1 | #3.非结构化方式新建索引 |
1 | #9.使用结构化的方式创建索引 |
索引复杂语句
1 | #13.带关键字条件的查询 |
match和term区别:https://www.cnblogs.com/yjf512/p/4897294.html
match 分词查询
term 整体查询
ElasticSearch高级语法及应用
更着重于分词相关的操作
analyze分析过程
analyse分析=分词的过程:字符过滤器-->字符处理-->分词过滤(分词转换,词干转化)
- 字符过滤:使用字符过滤器转变字符。
- 文本切分为分词:将文本(档)分为单个或多个分词。
- 分词过滤:使用分词过滤器转变每个分词。
- 分词索引:最终将分词存储在Lucene倒排索引中。
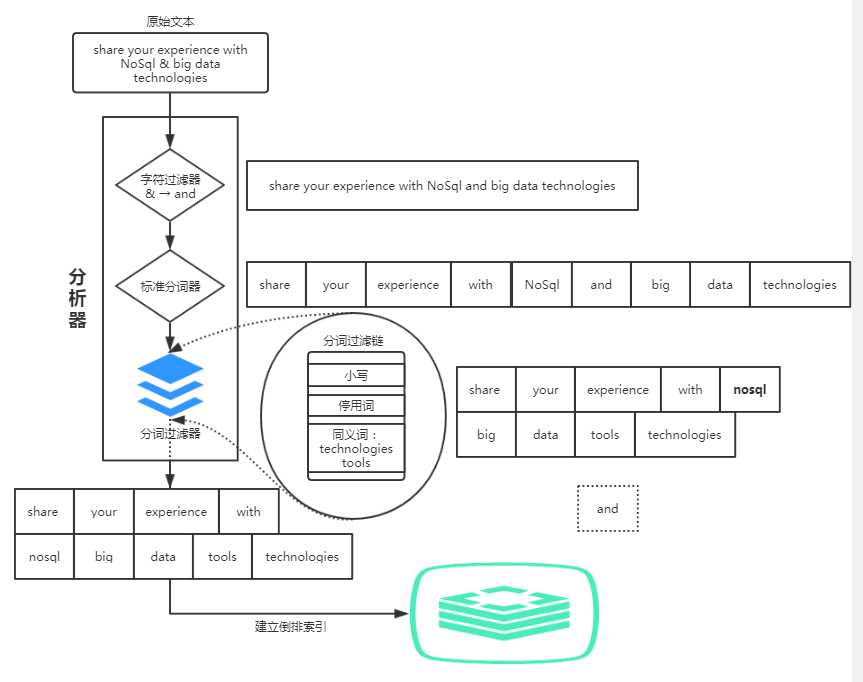
利用analyze api搜索
先建立索引
1 | PUT /employee/_doc/1 |
然后搜索
1 | GET /employee/_search |
没搜到后使用analyze api查看分析处理结果,可以看到没有分出eat,所以搜不到,改成用english分词器做索引
1 | GET /employee/_analyze |
重新创建索引
1 | PUT /employee |
在用analyze api,可以看到eat
1 | GET /employee/_analyze |
相关性查询手段
类型: