Zookeeper知识点总结
Zookeeper概述
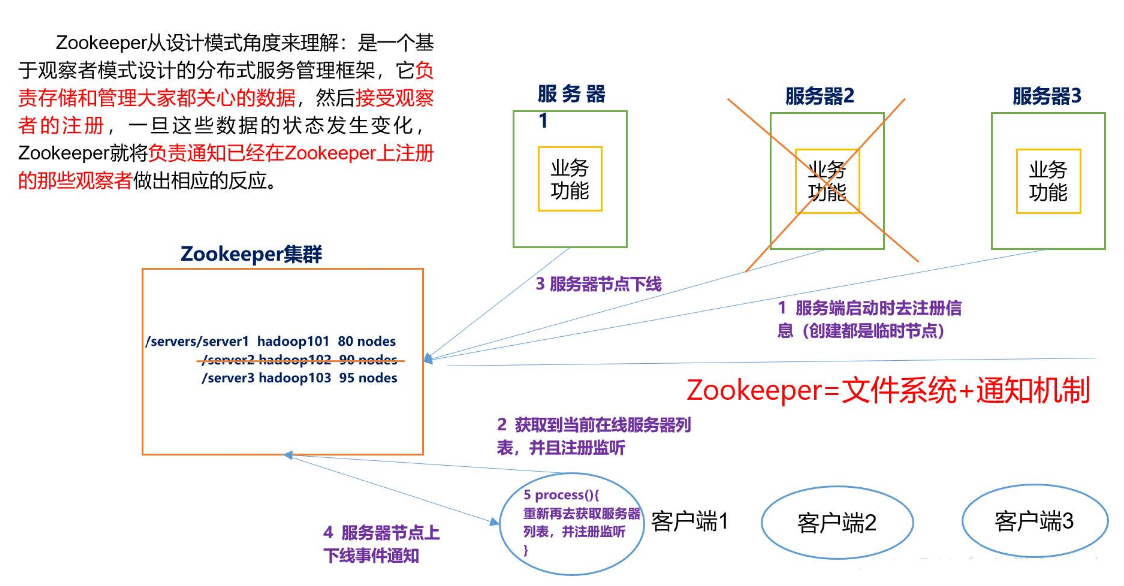
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。Zookeeper是基于分布式计算的核心概念而设计的,主要目的是给开发人员提供一套容易理解和开发的接口,从而简化分布式系统构建的服务。
Zookeeper是一个分布式协调服务的开源框架,它是由Google的Chubby开源实现。Zookeeper主要用来解决分布式集群中应用系统的一致性问题和单点故障问题,例如如何避免同时操作同一数据造成脏读的一致性问题等。
Zookeeper具有全局数据一致性、可靠性、顺序性、原子性以及实时性,可以说Zookeeper的其他特性都是为满足Zookeeper全局数据一致性这一特性。
1.全局数据一致
每个服务器都保存一份相同的数据副本,客户端无论连接到集群的任意节点上,看到的目录树都是一致的(也就是数据都是一致的),这也是Zookeeper最重要的特征。
2.可靠性
如果消息(对目录结构的增删改查)被其中一台服务器接收,那么将被所有的服务器接收。
3.顺序性
Zookeeper顺序性主要分为全局有序和偏序两种,其中全局有序是指如果在一台服务器上消息A在消息B前发布,则在所有服务器上消息A都将在消息B前被发布;偏序是指如果一个消息B在消息A后被同一个发送者发布,A必将排在B前面。无论全局有序还是偏序,其目的都是为了保证Zookeeper全局数据一致。
4.数据更新原子性
一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态。
5.实时性
Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
Zookeeper集群是一个主从集群,它一般是由一个Leader(领导者)和多个Follower(跟随者)组成。此外,针对访问量比较大的Zookeeper集群,还可新增Observer(观察者)。Zookeeper集群中的三种角色各司其职,共同完成分布式协调服务。
1.Leader它是Zookeeper集群工作的核心,卫是事务性请求(写操作)的唯一调度和处理者,它保证集群事务处理的顺序性,同时负责进行投票的发起和决议,以及更新系统状态。
2.Follower它负责处理客户端的非事务(读操作)请求,如果接收到客户端发来的事务性请求,则会转发给Leader,让Leader进行处理,同时还负责在Leader选举过程中参与投票。
3.Observer它负责观察Zookeeper集群的最新状态的变化,并且将这些状态进行同步。对于非事务性请求可以进行独立处理;对于事务性请求,则会转发给Leader服务器进行处理。它不会参与任何形式的投票,只提供非事务性的服务,通常用于在不影响集群事务处理能力的前提下,提升集群的非事务处理能力(提高集群读的能力,也降低了集群选主的复杂程度)。
工作机制
数据模型
Zookeeper是由节点组成的树,树中的每个节点被称为—Znode。每个节点都可以拥有子节点。每一个Znode默认能够存储1MB的数据,每个Znode都可以通过其路径唯一标识,如图中第三层的第一个Znode,,它的路径是/app1/p_1。Zookeeper数据模型中每个Znode都是由三部分组成,分别是stat、data、children。
Znode的类型
Znode的类型在创建时被指定,一旦创建就无法改变。
Znode有两种类型,分别是临时节点和永久节点。
临时节点:该生命周期依赖于创建它们的会话,一旦会话结束,临时节点将会被自动删除,也可以手动删除。虽然每个临时的Znode都会绑定一个客户端,但它们对所有的客户端还是可见的。需要注意的是临时节点不允许拥有子节点。
永久节点:该生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,它们才能被删除。
Znode的属性
| 属性名称 | 相关说明 |
|---|---|
| czxid | 节点被创建的时间 |
| ctime | 节点最后一次的修改的Zxid值 |
| mzxid | 节点最后一次的修改时间 |
| mtime | 与该节点的子节点最后一次修改的Zxid值 |
| pZxid | 子节点被修改的版本号 |
| cversion | 节点被创建的时间 |
| dataVersion | 数据版本号 |
| aclVersion | ACL版本号 |
| ephemeralOwner | 如果此节点为临时节点,那么该值代表这个节点拥有者的会话ID;否则值为0 |
| dataLength | 节点数据域长度 |
| numChildren | 节点拥有的子节点个数 |
Zookeeper的Watcher机制
在ZooKeeper中,引入了Watch机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事件触发了这个Watch,那么就会向指定客户端发送一个事件通知,来实现分布式的通知功能。
- 一次性触发
- 事件封装
- 异步发送
- 先注册再触发
| 连接状态 | 状态含义 | 事件类型 | 事件含义 |
|---|---|---|---|
| Disconnected | 连接失败 | NodeCreated | 节点被创建 |
| SyncConnected | 连接成功 | NodeDataChanged | 节点数据变更 |
| AuthFailed | 认证失败 | NodeChildrentChanged | 子节点数据变更 |
| Expired | 会话过期 | NodeDeleted | 节点被删除 |
Zookeeper的选举机制
Zookeeper为了保证各节点的协同工作,在工作时需要一个Leader角色,而Zookeeper默认采用FastLeaderElection算法,且投票数大于半数则胜出的机制。
- 服务器ID:设置集群myid参数时,参数分别为服务器1、服务器2、服务器3,编号越大
FastLeaderElection算法中权重越大。 - 选举ID:选举过程中,Zookeeper服务器有四种状态,分别为竞选状态、随从状态、观察状态、领 导者状态。
- 逻辑时钟:逻辑时钟被称为投票次数,同一轮投票过程中逻辑时钟值相同,逻辑时钟起始值为0, 每投一次票,数据增加。与接收到其它服务器返回的投票信息中数值比较,根据不同值做出不同判 断。
- 数据ID:是服务器中存放的最新数据版本号,该值越大则说明数据越新,在选举过程中数据越新 权重越大
Zookeeper选举机制有两种类型,分别为全新集群选举和非全新集群选举。全新集群选举是新搭建起来 的,没有数据ID和逻辑时钟的数据影响集群的选举;非全新集群选举时是优中选优,保证Leader是Zookeeper集群中数据最完整、最可靠的一台服务器。
假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没 有历史数据,在存放数据量这一点上,都是一样的。
假设这些服务器依序启动,来看看会发生什么
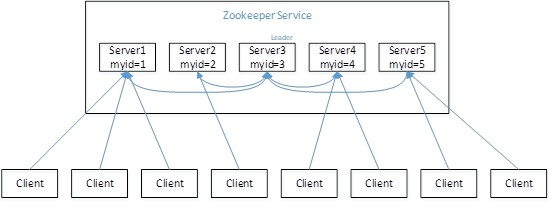
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3 票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现 服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票, 服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器
1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服 务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。 交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器 3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
Zookeeper分布式集群部署
Zookeeper分布式集群部署指的是ZooKeeper分布式模式安装。Zookeeper集群搭建通常是由2n+1台 服务器组成,这是为了保证 Leader 选举(基于Paxos算法的实现)能够通过半数以上台服务器选举支持,因此ZooKeeper集群的数量一般为奇数台。
官网首页:https://zookeeper.apache.org/
ZooKeeper下载地址:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.7/
1.上传Zookeeper安装包。将下载完毕的Zookeeper安装包上传至Linux系统/export/software/目录下。
1 | mv ~/apache-zookeeper-3.5.7-bin.tar.gz /export/software/ |
2.解压
1 | tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /export/servers/ |
3.修改Zookeeper的配置文件。先将zoo_sample.cfg配置文件重命名为zoo.cfg
1 | cp zoo_sample.cfg zoo.cfg |
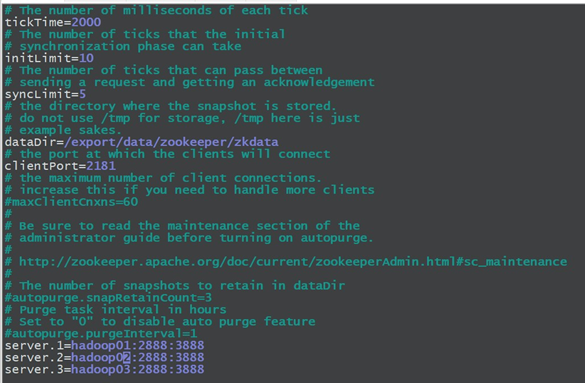
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1.tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是
2.initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime 的量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
3.syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4.dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
5.clientPort =2181:客户端连接端口监听客户端连接的端口。
6.server.1=hadoop01:2888:3888:配置zK集群的服务器编号以及对应的主机名、选举端口号和通信端口号(心跳端口号)
1 | mkdir -p /export/data/zookeeper/zkdata |

分发:
1 | scp -r /export/servers/apache-zookeeper-3.5.7-bin/ hadoop02:/export/servers/ scp -r /export/servers/apache-zookeeper-3.5.7-bin/ hadoop03:/export/servers/ scp -r /export/data/zookeeper/ hadoop02:/export/data/ |
启动和关闭:
1 | zkServer.sh start |
zkS.sh:
1 |
|



Zookeeper的Shell操作
1 | zkCli.sh -server localhost:2181 |
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path [watch] | 使用 ls 命令来查看当前znode中所包含的内容 |
| ls2 path [watch] | 查看当前节点数据并能看到更新次数等数据 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path [watch] | 获得节点的值 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| rmr | 递归删除节点 |
应用场景,HA、kafaka、HBase
1 | #启动客户端 |
Zookeeper的API应用
pom.xml中加入
1 | <dependency> |
1 | package test.com.test.zk; |